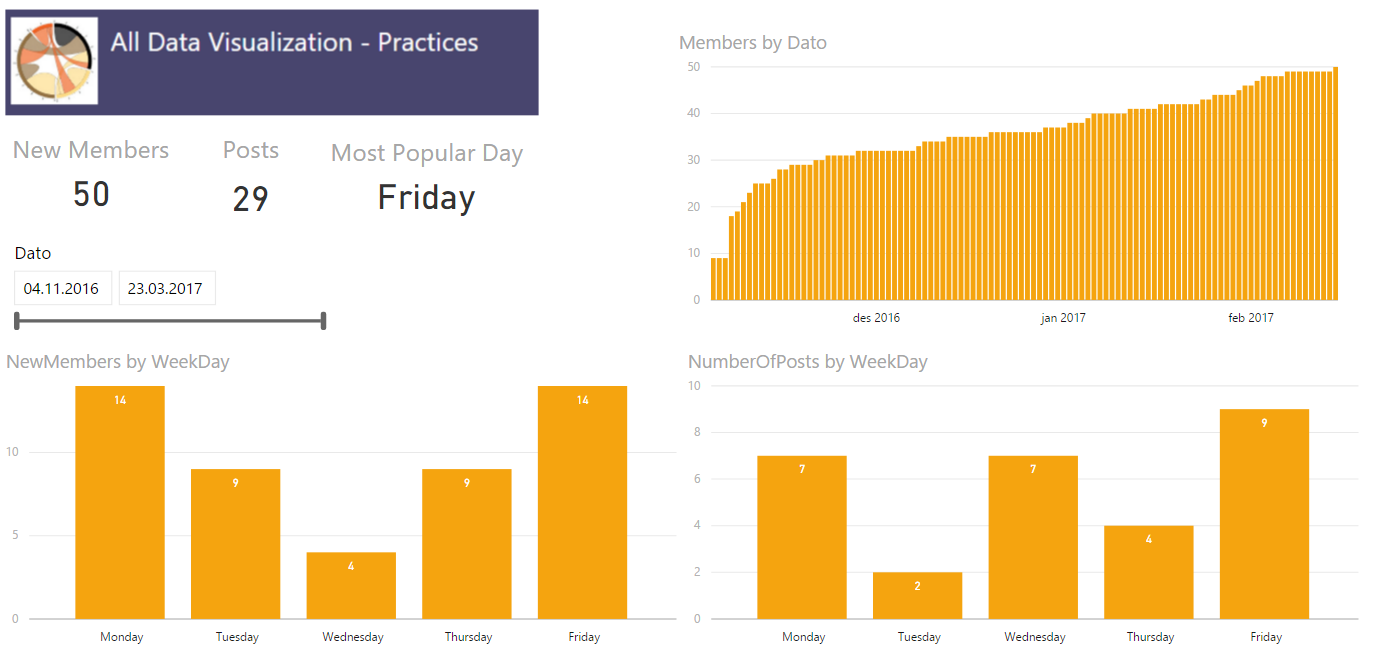
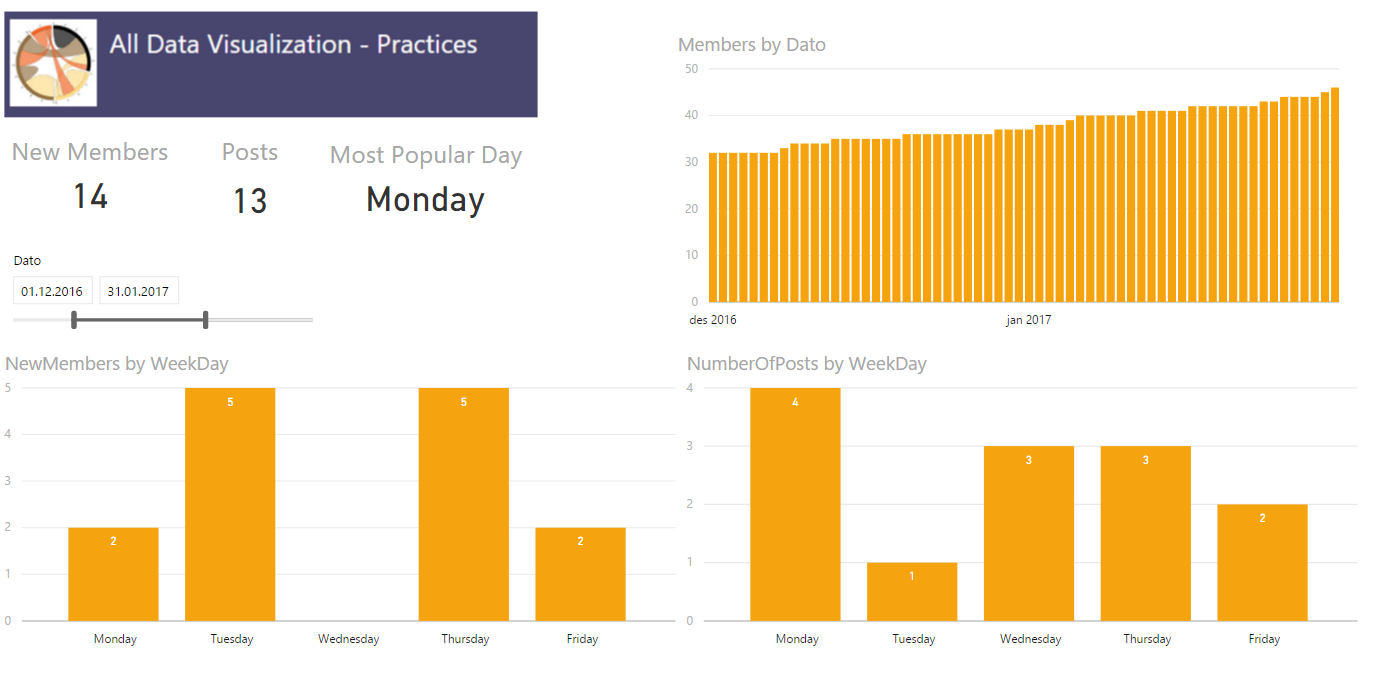
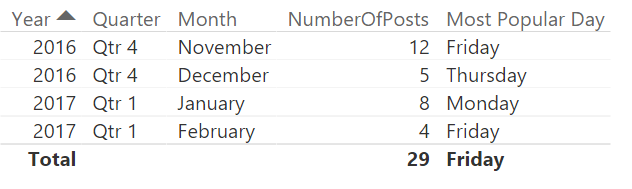
A very normal calculation we do is to compare a value, for example sales, against how we did last year. The easiest way to do this is by using the SAMEPERIODLASTYEAR function to create a measure that look like this
Sales LY = CALCULATE( [Sales] ;SAMEPERIODLASTYEAR(DimDate[Date]) )
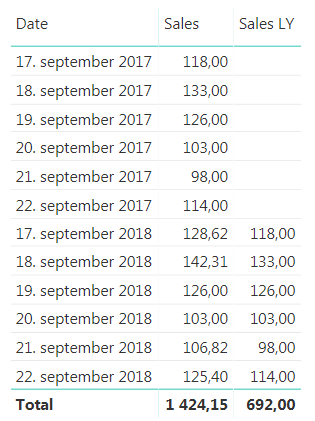
As shown in the image above this works fine for a given date, but what if we want to look at how one week compared to last year? For retailers this is a very normal demand. ow can we compare monday in one week to monday in the same week last year? After all it is a big difference in how much sales is being done on a Saturday compared to a Sunday, the shop might even be closed on sunday. For this we need to create a calculated column to help us out. We are going to call it DWY (for DayWeekYear) and we can do it like this
DWY = WEEKDAY(DimDate[Date])*1000000 + WEEKNUM(DimDate[Date])*10000 + YEAR(DimDate[Date])
Note: For people not using American calender you may need to prep week number otherwise to get ISO week, for example in your date dimension. Then you can do the calculation. The important part is that is lines up with your definition of day in week, week number and year.
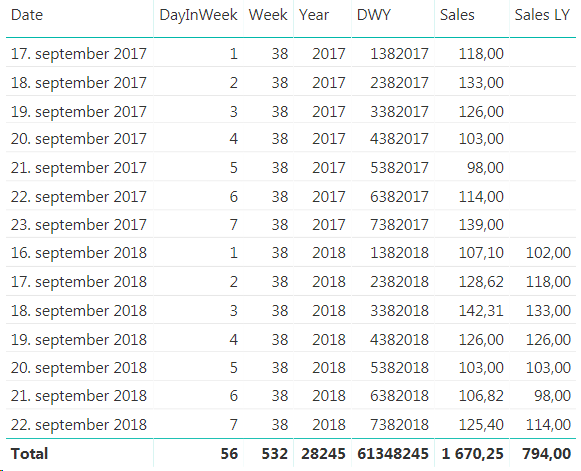
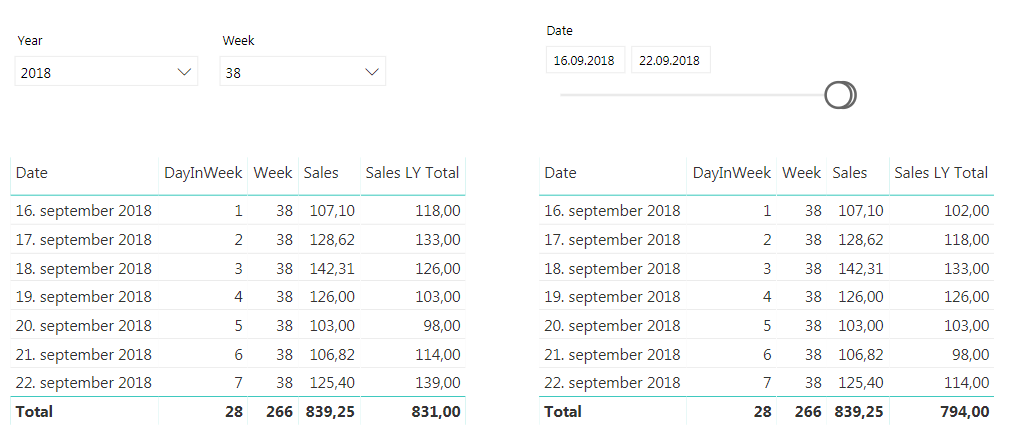
Here you can see that 17th of September 2017 is a Monday, but in 2018 it is a Tuesday so we are unable to compare the two. Now, the beauty here with our new DWY column is that if we subtract one from a DWY date this year we get the same day in the same week last year. So, DWY Last Year = DWY -1. Which is great! So we can use this to create a measure that compares day in week vs the same day in week last year.
Sales LY Week = Calculate ( [Sales] ;Filter(ALL(DimDate); DimDate[DWY] = Max( DimDate[DWY])-1) )
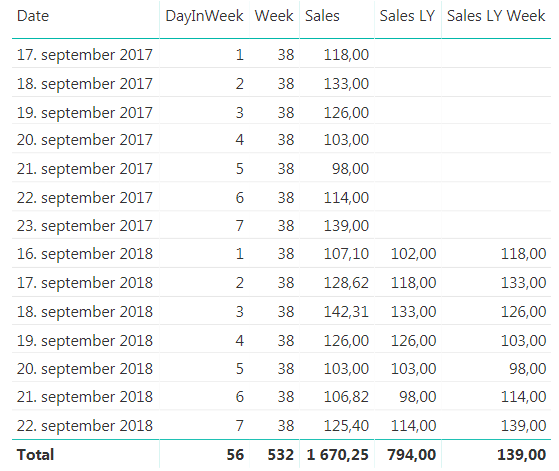
This works great when we look at a specific date, but you will see that the total row for the new measure is the same as the last value, and not the sum, so we have to extend it a little bit to make it sum up all the days we are showing. To do this we will use the SUMX function to create this measure
Sales LY Week Total = SUMX ( VALUES(DimDate[DWY]) ;FactSales[Sales LY Week] )
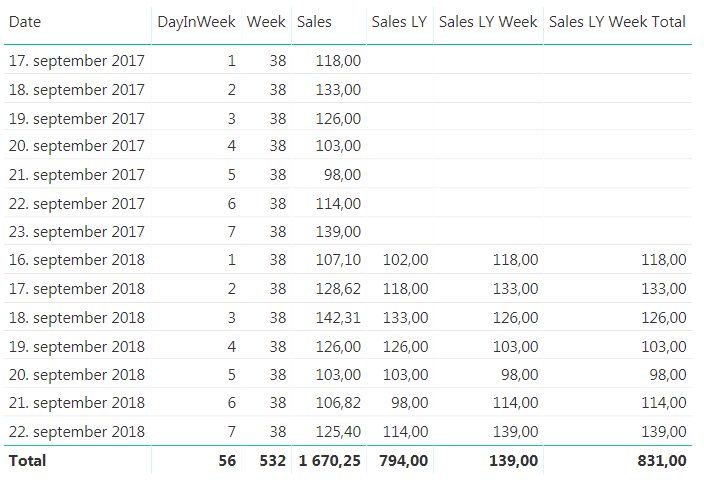
There you have it. But can we do more? In general I don’t like having more than one measure saying the same thing. We are looking at sales for last year in both measures we have created, it is just that one is comparing with a specific date and one is comparing with day in week. I would like to just have one measure that is Sales Last Year and then we can say that if the user is filtering on a week or a weekday we will show them the day in week last year value and otherwise we will show them the specific date. Now, this might be on a case to case scenario, but if you keep both measures available to they users they will have to remember that they cannot use the Sales LY Week Total measure if they want to look at a specific date, they have to use the “normal” Sales LY measure. In my experience this is often a source for user errors that might be confusing so we can hide this complexity by combining the measure we have created.
Sales LY Total = IF ( ISFILTERED(DimDate[Week]) || ISFILTERED(DimDate[DayInWeek]) ;FactSales[Sales LY Week Total] ;FactSales[Sales LY] )
The finished result will behave as shown below. The same measure is used in both tables, but the one on the left is filtered on week while the one on the right is filtered by dates. If you have more ways of showing week or week day in your date dimension, like the week day name remember to include them in the IF statement to make them work as we want them to.